

与稀缺性相比,数据的丰富性更能促成AI创新 | 论文精选
2022-05-04- 报告 · 研报 · 论文-

本文推送精选一篇刊登在2020年的NBER Working Paper Series的来自Martin Beraja, David Y. Yang & Noam Yuchtman 的working parper《数据密集型创新与国家:来自中国人工智能公司的证据》中的核心观点。
本文只呈现了该报告的部分关键点,完整报告可通过高礼智库(搜索框输入报告题目关键词即可)下载。
摘要
人工智能技术的开发与创新离不开海量数据的支持。在许多领域,政府收集的数据的规模和范围都远远超过了私营部门收集的数据,而AI公司在为国家提供服务时通常能够取得访问这些数据的权限。
本文认为,这种访问可以刺激商业人工智能创新,部分原因是数据和经过训练的算法可以在政府和商业用途之间共享。为此,研究者收集了有关中国人脸识别AI行业公司和公共安全采购合同的全面信息并通过测算公共安全机构收集监控视频的能力来量化这些公司通过政企间合同可访问的数据。
在计量分析的过程中,本文研究者使用三重差异DDD策略发现:与数据稀缺的合同相比,数据丰富的合同会导致数据接收的公司开发出明显且实质上更多的商业AI软件。最终本文得出结论:政府数据在中国人脸识别AI公司的崛起中做出了积极贡献,同时表明,国家的数据收集和提供政策可能会塑造AI创新。
Points
理论分析
本文将AI企业用于训练的原始数据集按来源分为政府收集数据和私人部门收集数据两类,将AI企业开发的AI软件按用途划分为商业软件和政府软件,并假设两类数据可以交叉应用在两类软件中,公司获得的合同则依据可访问数据量划分为数据丰富合同和数据稀缺合同。
在构建了基础的生产模型之后,本文考虑了固定政府合同中非数据量特征以及企业自身生产特征后由于政府合同带来的政府数据集差异对最终产出的影响,即下图所示,其效应包含了直接影响和间接影响两部分。

这就是本文旨在估计的参数:即政府数据对商业软件开发的因果影响。它由两个元素组成:
(i)由于政府数据(或算法)的可共享性而产生的政府数据量提高的直接积极效应;
(ii)可放大或抑制——甚至逆转该直接影响的间接效应。
本文分析发现:当其他非数据共享性投入增加时,间接效应将会增加直接效应,例如因为公司管理和利用数据集的能力由于访问了更多的政府数据得到提高,这时直接效应也会得到提高。另一方面,当AI企业履行政企合同将对非共享性的投入形成挤出效应时,间接效应将倾向于抵消直接效应。
实证分析
通过理论分析推导,说明了本文估计所需效应参数所采用的实证方法:比较获得数据丰富合同与数据稀缺的合同的AI公司之间的商业软件产出的差异。同时它还揭示本文的实证部分所需要考虑的两个主要的识别变量的威胁:
(i)获得数据丰富合同的公司可能与获得数据稀缺合同的公司存在不同的企业特征,需要考虑企业特征的影响;
(ii)数据丰富的合同在可能除了提供的政府数据量以外,与数据稀缺的合同存在其他差异,即需要考虑其他混杂因素的影响。
数据源
本文采用的数据源为7,837家中国面部识别人工智能公司,以及从中国财政部维护的中国政府采购数据库中提取的中国各级政府2013年至2019年发布的2997105份采购合同的信息,重点关注公共安全机构授予人工智能公司的合同,以分析来自当地监控网络的数据。

数据处理
1、将中国的面部识别人工智能公司与政府合同联系起来
为了识别获取人脸识别人工智能的公共安全合同,本文将这些合同与人脸识别人工智能公司的名单进行了匹配,确定了至少涉及的28,023个采购合同一家面部识别人工智能公司。同时,许多公司收到了多份合同,总的来说,本文的所用的数据集中,有1095家面部识别人工智能公司至少收到了一份合同。
2、对新型面部识别人工智能软件产品进行计数和分类
通过对世界上第一家面部识别人工智能公司MegVii的IPI招股说明书进行交叉核对,能够验证本文所提出的对软件发布的衡量标准的全面性和可靠性。最终,本文能够在软件客户分类中达到72%的中位数准确率,而在验证数据中的软件功能分类中达到98%的中位数准确率。
3、衡量公司可以访问的政府数据的数量
在公共安全AI合同中,我们确定了那些可能为面部识别AI公司提供的数据丰富合同。同时计算了当地公共安全部门所购买的高清监控摄像头所提供的数据量。
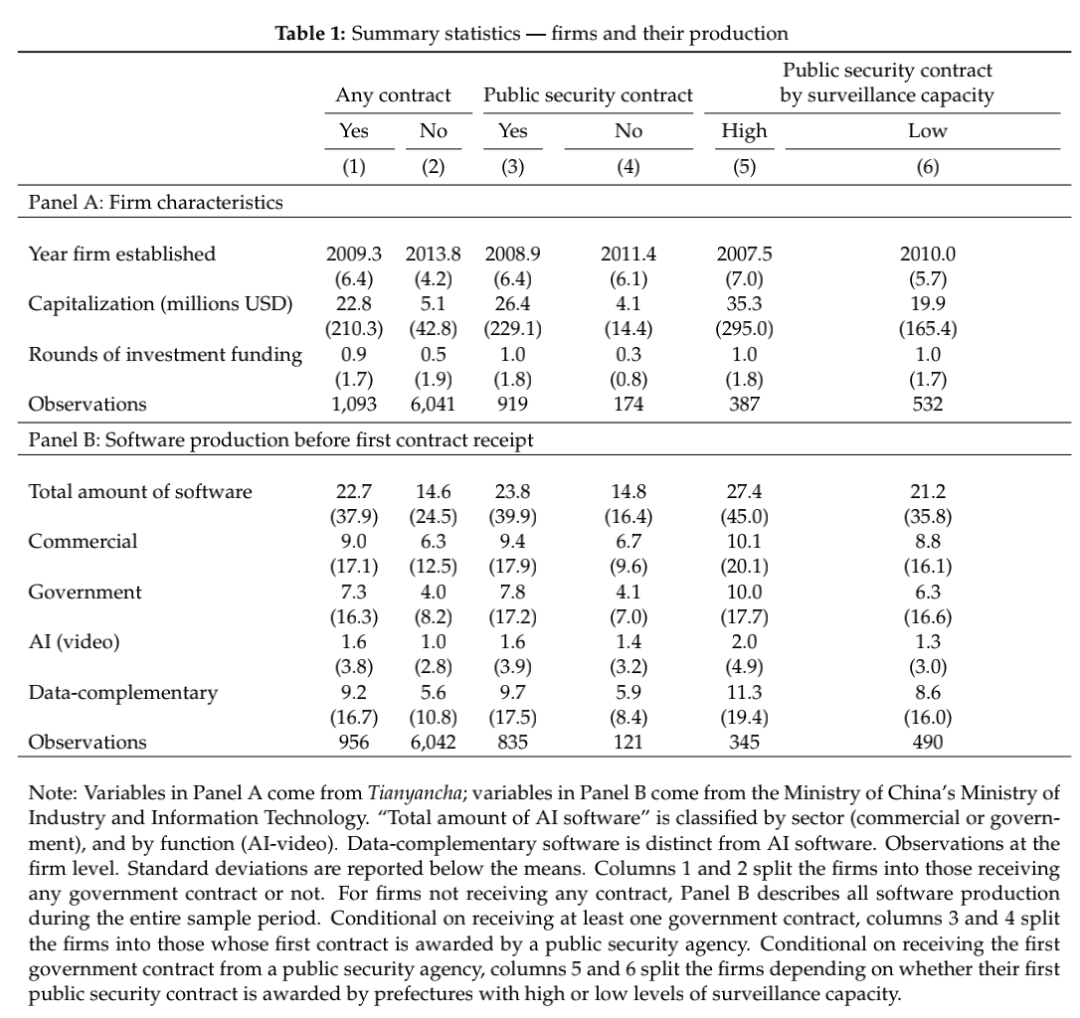
计量分析
1、模型构建
本文测试了接受数据丰富公共安全合同的公司在收到合同后是否会不同程度地增加他们的商业软件生产。为此,构建经验模型如下:
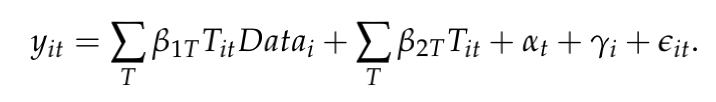
其中结果变量是由公司i到6个月期间t的商业软件发布的累积数量。本文感兴趣的解释变量是一组变量之间的交互项,即虚拟变量,表示在公司收到第一个合同之前或之后的6个月的时间段,以及另一个虚拟变量,用于衡量公司的第一个合同是否数据丰富。
2、对目标参数的Baseline估计和参数回归分析
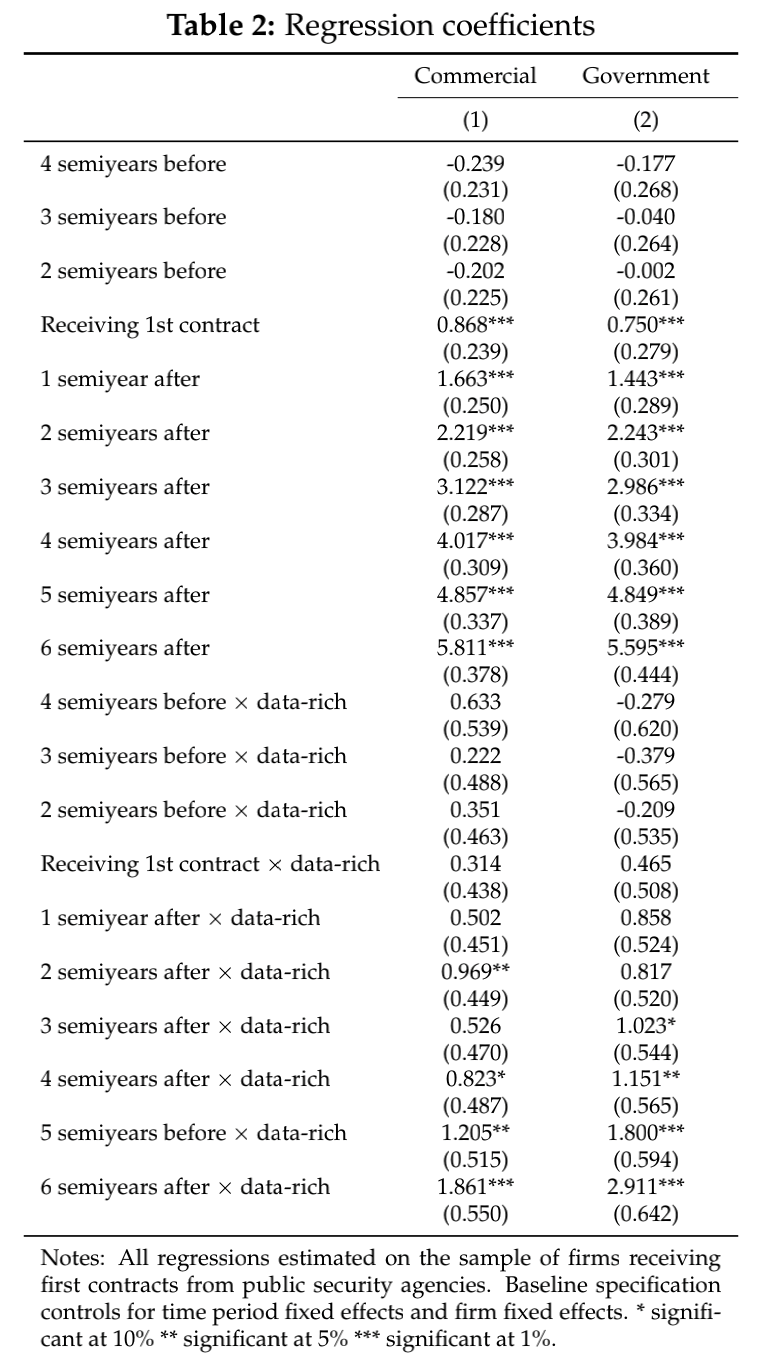
下图a、b分别表示的是商业用软件产出(a)和政府用软件产出(b)在不同时间点上系数的变化以及其95%置信区间,用于描述在企业在收到数据丰富的公共安全合同时,相对于数据稀缺的公共安全合同的所产生的累积软件产出量差异。
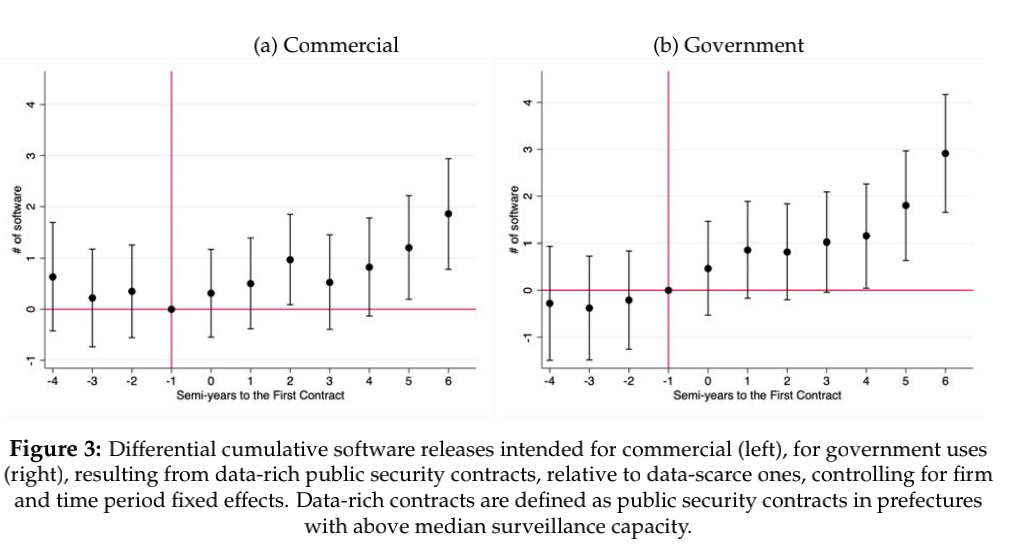
研究者发现,相较于收到数据稀缺合同,收到数据丰富合同对企业的商业软件产出有较大的提升作用,具体体现为:企业在收到合同一年后再增加约1.0个软件产品,在合同签订后的3年内再增加到约1.9个软件产品。在3年的时间跨度上,这意味着商业软件的产量相对于合同前的水平增加了20.2%。
同时,本文也发现,与签订数据稀缺合同相比,签订数据丰富的公共安全合同会让企业在收到合同后的3年内产生了2.9个额外的政府用软件产品(增加了约51.9%)。
更重要的是,本文发现政府用软件生产不存在水平或趋势的签订合同前差异。因此,尽管依然存在向政府用软件开发分配资源的倾向,但商业软件的生产仍在以更快的速度增加,这体现了我国AI产业发展过程中。
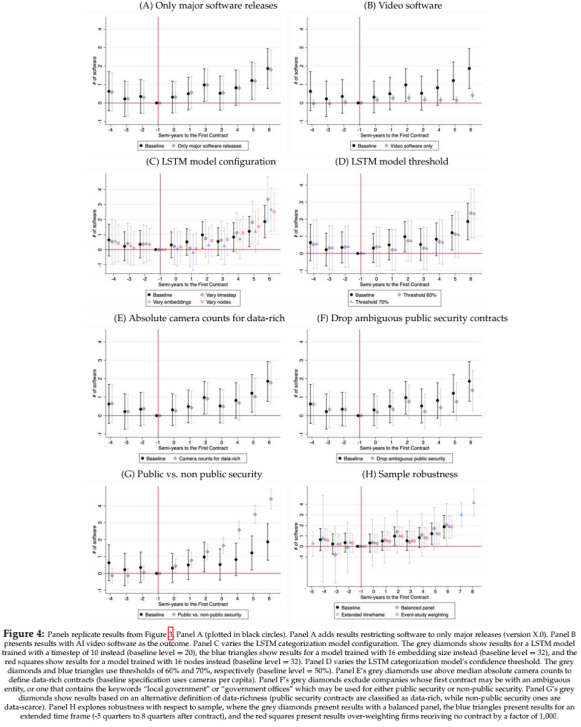
3、稳健型检验
在稳健性检验的过程中,本文作者分三步进行:
(i)首先,检验影响企业软件创新产出的变量。
(ii)其次,本文还考虑了我们用于分类软件的RNN算法中所选择的三个关键参数——时间步长、嵌入和节点。
(iii)最后,本文重新评估了对数据丰富的采购合同的定义来检验研究结果的稳健性。
4、模型评估与机制分析
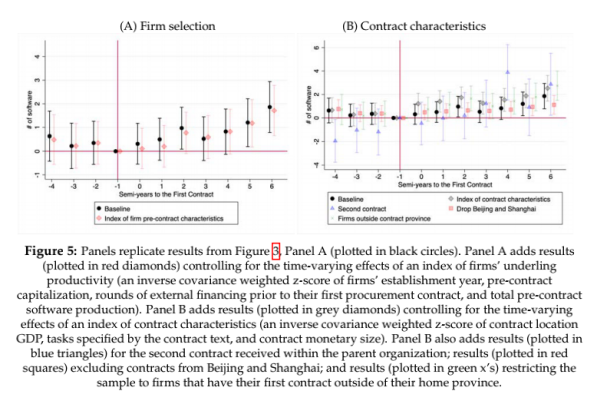
(i)替代假设评估
在这部分,作者考虑了除合同中政府提供数据量差异以外的影响,分别是企业对数据丰富合同的偏好和自主选择以及除政府数据差异以外的合同特征。最终发现,上述特征并不会在定性或定量上影响baseline估计。此外,因为收到数据丰富合同可能作为公司质量或潜力的信号,通过它公司可以获得额外的生产性投入,结果发现在这一方面的影响下,接受数据丰富合同仍然有显著的差异影响。
(ii)机制分析
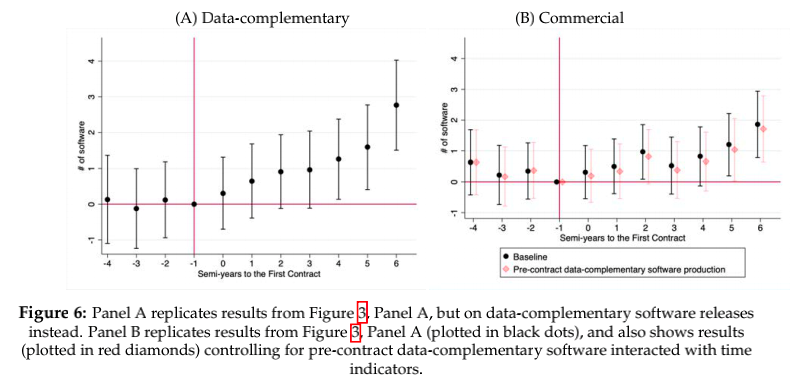
本文还对该作用机制中政府其他非数据类型的共享性投入对AI企业软件开发创新产出的直接与间接影响进行了更深层次的探讨,最终发现如果非数据共享的输入能够baseline估计的结果,那么这些控制将显著改变我们的估计,但根据下图,这一影响是近乎可以忽略的,这进一步说明了可共享的政府数据(和算法)对商业软件生产的重要的直接影响。
总结
在本文中,首次提供了政府数据对商业人工智能创新的因果效应的证据。这种效应背后的一个重要机制是,数据和训练过的AI算法可跨政府和商业用途共享。在本文的经验背景下,该研究结果表明,由于政府向为国家提供服务的中国人工智能公司提供了丰富数据,这些企业成为了面部识别技术的全球领导者。更普遍地说,我们所强调的经济机制可以适用于政府数据所在的一系列其他重要领域,特别是地理空间和健康数据领域。同时,这也意味着其他国家的人工智能采购和数据提供可以作为一项重要的创新政策推动人工智能在许多领域的发展。
目录
引言
一、理论框架
二、国家和中国人脸识别AI产业发展
2.1 实证内容
2.2 数据源
三、经验分析
3.1 实证模型与识别策略
3.2 对于目标变量的基线(Baseline)估计
3.3 替代假设估计
3.4 机制评价
四、总结